import marimo as mocloudposterior: Parallel model comparison
cp.map fits many models at once on the cloud – the canonical parallel Bayesian workflow. Here we fit three increasingly-pooled radon models concurrently and compare them with LOO cross-validation.
Run this notebook locally (Jupyter or marimo).
cp.mapprints job-level progress inline and serves a live dashboard for the per-model detail.
import arviz as az
import pandas as pd
import pymc as pmStart fresh
Clear any cached fits and this project’s Modal volume so the notebook runs cold and reproducibly. (Shown in marimo; hidden in the rendered notebook.)
import shutil
from pathlib import Path
import cloudposterior as cp
# Wipe the local result cache + this project's Modal volume so the example
# starts cold. The cp.map cells below use `cp`, so marimo runs this first.
shutil.rmtree(Path(".cloudposterior"), ignore_errors=True)
cp.cleanup_volumes()/Users/spencerboucher/Projects/cloudposterior-map-dashboard/cloudposterior/backends/modal_backend.py:790: AsyncUsageWarning: A blocking Modal interface is being used in an async context.
This may cause performance issues or bugs. Consider rewriting to use Modal's async interfaces:
https://modal.com/docs/guide/async
Suggested rewrite:
await modal.Volume.objects.delete.aio(volume_name)
Original line:
modal.Volume.objects.delete(volume_name)Data
919 household radon measurements across 85 Minnesota counties (Gelman & Hill, 2006).
df = pd.read_csv(pm.get_data("radon.csv"))
counties = df.county.unique()
county_idx = df.county_code.values
log_radon = df.log_radon.values
floor = df.floor.valuesThree models
- Complete pooling – one intercept for all counties (ignores county).
- Hierarchical – partial pooling: county intercepts shrink toward a shared mean.
- Unpooled – an independent intercept per county (no sharing).
All three share a floor (basement vs first-floor) fixed effect. We build them in one cell so each name is defined once (marimo’s single-definition rule).
with pm.Model(name="pooled") as pooled:
a = pm.Normal("a", 0, 5)
b = pm.Normal("b_floor", 0, 5)
sigma = pm.HalfNormal("sigma", 2)
pm.Normal("obs", a + b * floor, sigma, observed=log_radon)
with pm.Model(name="hierarchical", coords={"county": counties}) as hierarchical:
mu_a = pm.Normal("mu_a", 0, 5)
sigma_a = pm.HalfNormal("sigma_a", 2)
a_raw = pm.Normal("a_raw", 0, 1, dims="county")
a = pm.Deterministic("a", mu_a + sigma_a * a_raw, dims="county")
b = pm.Normal("b_floor", 0, 5)
sigma = pm.HalfNormal("sigma", 2)
pm.Normal("obs", a[county_idx] + b * floor, sigma, observed=log_radon)
with pm.Model(name="unpooled", coords={"county": counties}) as unpooled:
a = pm.Normal("a", 0, 5, dims="county")
b = pm.Normal("b_floor", 0, 5)
sigma = pm.HalfNormal("sigma", 2)
pm.Normal("obs", a[county_idx] + b * floor, sigma, observed=log_radon)
models = [pooled, hierarchical, unpooled]Fit all three in parallel
cp.map uploads each model once and runs the fits concurrently on the cloud. Results come back in input order.
It also serves a live dashboard by default (printed as a link below): an overview of all three models that you can drill into for any single model’s chains, convergence, and live traces – with a global Stop all and a per-model Stop. Pass dashboard=False to opt out.
idatas = cp.map(models, {"draws": 1000, "tune": 1000, "chains": 4})cp.map: fitting 3 model(s) in parallel ...
cp.map: dashboard: https://justmytwospence--pooled-ba0fd9-dev.modal.run
cp.map: [1/3] done
cp.map: [2/3] done
cp.map: [3/3] doneCompare with LOO
Compute pointwise log-likelihood locally (cheap, no resampling), then rank the models by leave-one-out cross-validation. The hierarchical model usually wins: partial pooling beats both the over-confident unpooled fit and the over-smoothed complete-pooling fit.
for _model, _idata in zip(models, idatas):
with _model:
pm.compute_log_likelihood(_idata)
comparison = az.compare(dict(zip(["pooled", "hierarchical", "unpooled"], idatas)))
comparisonComputing ... ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
Computing ... ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
Computing ... ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00/Users/spencerboucher/Projects/cloudposterior-map-dashboard/.venv/lib/python3.13/site-packages/arviz/stats/stats.py:782: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.70 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
warnings.warn(| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| hierarchical | 0 | -1036.853197 | 49.651593 | 0.000000 | 9.221251e-01 | 28.015256 | 0.000000 | False | log |
| unpooled | 1 | -1063.048812 | 87.256236 | 26.195615 | 6.536017e-14 | 28.565191 | 6.192207 | True | log |
| pooled | 2 | -1089.968650 | 3.828977 | 53.115454 | 7.787493e-02 | 24.994959 | 10.802147 | False | log |
az.plot_compare(comparison, figsize=(8, 3))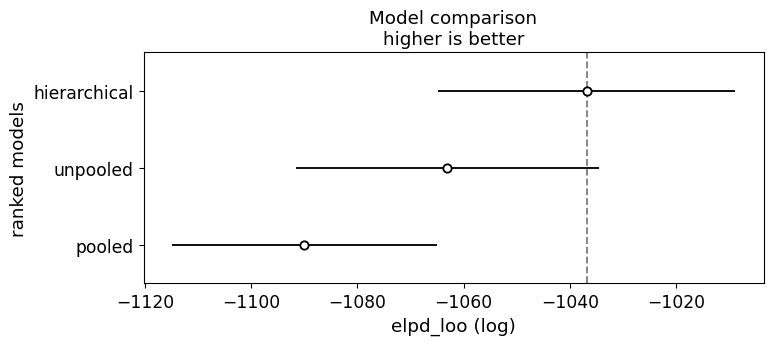
Adaptive early-stop with until
Pass until=True and each fit stops as soon as every scalar parameter clears the convergence target (R-hat <= 1.01, ESS >= 400), with draws= as the cap. The cheap pooled model converges in a few hundred draws while the richer models keep going – no compute wasted oversampling the easy ones. (nutpie / pymc, remote.)
_idatas_until = cp.map(models, {"draws": 4000, "tune": 1000, "chains": 4}, until=True)
# draws each model kept -- early-stop => fewer than the 4000 cap
{m.name: int(it.posterior.sizes["draw"]) for m, it in zip(models, _idatas_until)}cp.map: fitting 3 model(s) in parallel ...
cp.map: dashboard: https://justmytwospence--pooled-fc2f78-dev.modal.run
cp.map: [1/3] done
cp.map: [2/3] done
cp.map: [3/3] doneUnable to display output for mime type(s): application/jsonForcing a re-fit with overwrite
The first cp.map cached each fit, so a plain re-run is an instant cache hit (it prints all 3 cached). Pass overwrite=True to ignore the cache, refit every model, and replace the stored results – note it prints fitting 3 model(s) instead.
# Re-run ignoring the cache: refits all three (not a cache hit).
_idatas_overwrite = cp.map(models, {"draws": 1000, "tune": 1000, "chains": 4}, overwrite=True)cp.map: fitting 3 model(s) in parallel ...
cp.map: dashboard: https://justmytwospence--pooled-37978e-dev.modal.run
cp.map: [1/3] done
cp.map: [2/3] done
cp.map: [3/3] doneCleanup
cp.map provisions a project-scoped volume. Delete it when you’re done.
cp.cleanup_volumes()/Users/spencerboucher/Projects/cloudposterior-map-dashboard/cloudposterior/backends/modal_backend.py:790: AsyncUsageWarning: A blocking Modal interface is being used in an async context.
This may cause performance issues or bugs. Consider rewriting to use Modal's async interfaces:
https://modal.com/docs/guide/async
Suggested rewrite:
await modal.Volume.objects.delete.aio(volume_name)
Original line:
modal.Volume.objects.delete(volume_name)